
I go through the occasional bout of nostalgia, I admit it. Sometimes I muse that it would have been much more fun to be alive during the Wild West, or during the American Revolutionary War. Mostly this is clearly symptomatic of the fact that I feel disconnected and I want to feel a part of a movement, something significant that is taking hold of history and making it sit up and pay attention.
While I lived in Paris I was privileged to see the works of infamous, modern-era, groundbreaking schools of art such as the Blau Reiter, the Futurists, Alexander Calder and the mobile sculptors, Impressionists, Fauvists, Surrealists, Cubists, Pointillists, you name it. As I browsed the carefully curated collections of work and imagined what it would be like to exist in a time of such intense creation, innovation and turn-the-world-on-its-head thinking, I remember thinking: does anyone really ever know when they’re living smack-dab in one of those eras?
Now that I’m back in the U.S. working, and no longer have the luxury of wandering the streets of Paris, being a flaneur and contemplating my navel, those questions have gone mostly by the wayside in favor of, oh, I dunno, buying toilet paper and writing corporate emails again. Sigh. However, they don’t have to because it may actually be true that we are in the middle of a cohesive burgeoning artistic, cultural and technological movement! It even has a name, folks, which is huge, because without a name it will be hard to reference it: The New Aesthetic.
What is it about? Well, significantly it’s pretty all-encompassing, which it has to be in this era of multimedia, consolidated and integrated channels, myriad communication modes and access. In a nutshell (though that is a depressingly analog expression to use in this context) it’s about taking the time to understand how technology is affecting and has already impacted the way we see the world, how we see everything. The movement focuses on the presumption that most of the world increasingly now experiences the world not directly through their eyeballs, but through the eyes of a technological device- whether it’s a camera, a smartphone, GPS, a tablet, an e-reader, a computer screen, etc.

This opportunity for reflection is significant first because the pace of technology and its adoption simply hasn’t historically allowed us to do this- we adopt a technology, learn it, deploy it and then we’re off and running with barely a glance backward. In the super-charged modern era of technology have we really reflected on its impact on how we see things? Yes, the visionary artists, influencers and politicians of our time have, in small numbers. But this movement finally has identified certain themes about how we have all been shaped by new technologies and it’s just so interesting.
Another great facet of the New Aesthetic is in how it is playing out. This is not a genre that is reserved for the intellectual or artistic elite. So far the movement has invited everyone to participate, thereby furthering the impact that the act of reflecting has. It begs questions of its members-How is the world different from how I saw it before? Can we actually evaluate if things were better or worse before this technology/gadget/access/knowledge? Show us what you see and how you see it. Can you find us other examples of where this is playing out?
From Bruce Sterling‘s Wired piece on the topic:
“The “New Aesthetic” is a native product of modern network culture…it was born digital, on the Internet. The New Aesthetic is a “theory object” and a “shareable concept.”
The New Aesthetic is “collectively intelligent.” It’s diffuse, crowdsourcey, and made of many small pieces loosely joined. It is rhizomatic, as the people at Rhizome would likely tell you. It’s open-sourced, and triumph-of-amateurs. It’s like its logo, a bright cluster of balloons tied to some huge, dark and lethal weight.” (http://www.wired.com/beyond_the_beyond/2012/04/an–essay–on–the–new–aesthetic/)
It should come as no surprise that this discussion largely began at the recent South by Southwest (SXSW) conference in Austin, Texas. Here is the description of the panel discussion:
“Slowly, but increasingly definitively, our technologies and our devices are learning to see, to hear, to place themselves in the world. Phones know their location by GPS. Financial algorithms read the news and feed that knowledge back into the market. Everything has a camera in it. We are becoming acquainted with new ways of seeing: the Gods-eye view of satellites, the Kinect’s inside-out sense of the living room, the elevated car-sight of Google Street View, the facial obsessions of CCTV.
As a result, these new styles and senses recur in our art, our designs, and our products. The pixelation of low-resolution images, the rough yet distinct edges of 3D printing, the shifting layers of digital maps. In this session, the participants will give examples of these effects, products and artworks, and discuss the ways in which ways of seeing are increasingly transforming ways of making and doing.” (http://schedule.sxsw.com/2012/events/event_IAP11102)
James Bridle is sort of the figurehead of the discourse around the New Aesthetic and he has done an excellent job of laying out what it means to him and helping to provide spaces for the conversation about it to unfold. In fact, he’s downright poetic in some of his descriptions:
“And what of the render ghosts, those friends who live in our unbuilt spaces, the first harbingers of our collective future? How do we understand and befriend them, so that we may shape the future not as passive actors but as collaborators? (I don’t have much truck with the “don’t complain, build” / “make stuff or shut up” school, but I do believe in informed consent. Because a line has been crossed, technology/software/code is in and of the world and there’s no getting out of it. ” (http://booktwo.org/notebook/sxaesthetic/)
“My point is, all our metaphors are broken. The network is not a space (notional, cyber or otherwise) and it’s not time (while it is embedded in it at an odd angle) it is some other kind of dimension entirely.
BUT meaning is emergent in the network, it is the apophatic silence at the heart of everything, that-which-can-be-pointed-to. And that is what the New Aesthetic, in part, is an attempt to do, maybe, possibly, contingently, to point at these things and go but what does it mean?” (http://booktwo.org/notebook/sxaesthetic/)
That’s good stuff, right? I think so.
But let’s take a step back from the philosophical implications of the movement and do some of our own shell collecting in the sand. Where do we see the New Aesthetic playing out?
Here’s a few that I found:
1) My latest favorite Tumblr: ScreenshotsofDespair. Apart from appealing to that deep and sinister Schadenfreude bone that I have, this Tumblr is a perfect example of the New Aesthetic. We take photos, of screens, which we see delivering ambiguous and subtly insulting messages that seem to mirror our own loneliness, unpopularity, failure,- despair. So good.

From "Screenshots of Despair"
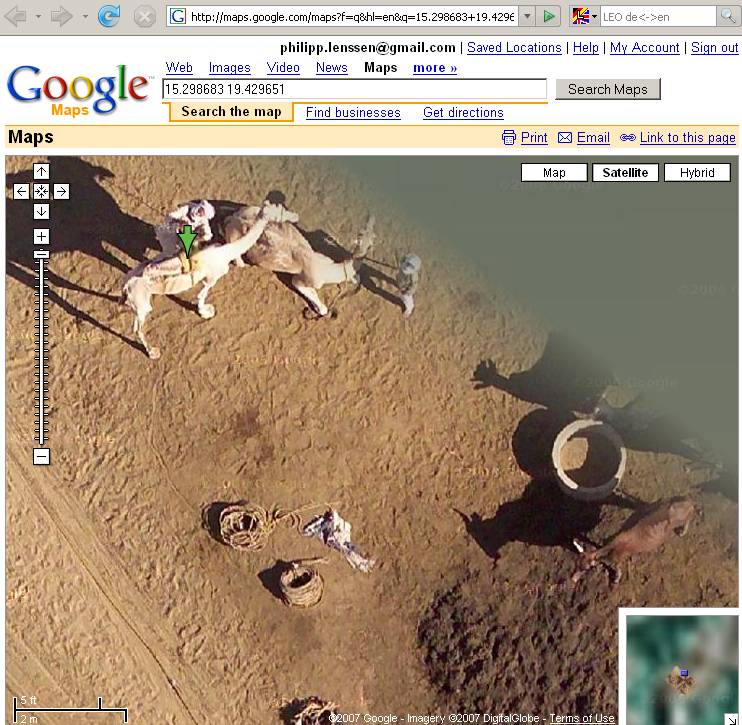
2) Where am I?: Google Maps and StreetView. The fact that we now actively use archived and ongoing screenshots of satellite maps and digital photography to represent to us what the world looks like, rather than having to travel there physically. I know what my friend Anna’s house looks like in Berlin without ever having been there, but I only know what it looks like on a sunny day- April 2nd, 2009.

3) Tweet-note: I’m coining this term (unless it has been coined before) to mean seeing a live event happen through the lens of what is being said about it by the Twitter-verse. See my piece on “sentiment analysis” for a more nuanced examination of the implications of this, but it’s pretty crazy that these days (especially at ANY high-tech conference) you can sit in a room of thousands of people, listeningto/watching the same keynote, and yet about 98% of the audience is simultaneously tracking what is being said about that event via Twitter on their smartphones, thereby allowing the rest of the audience to largely color their opinion in real time.

4) Art: This is obvious, but the emergence of re-pixellating and bringing digital back to analog, and a nostalgia for real film is all playing out in the art world. The pixellation movement really interests me because it’s such a blatant reversion to pointillism, but it represents more of a re-education for a younger generation on how the greater whole is amassed as the result of millions and millions of tiny components. It’s also a throwback to so many other modernist movements- Duchamp’s Nude Descending a Staircase and Picasso’s Cubism comes to mind, especially here, when we talk about the New Aesthetic in terms of trying to represent the everywhere-at-once nature of things today. You can look at a book, just a simple book with your own eyes. But you can also look up reviews of the book on Amazon or Goodreads, you can research Google images of the book, how much people will pay for the book on eBay, you can read reviews of the book on the NYTimes, you can take a weathered antique-y snapshot of the book with Hipstamatic, text message your friend about the book with its photo attached, and many other options that I can’t even think of right now. All of that is a more than 360 degree representation of that book: what it is, what it looks like, what it represents, where it is, and how it is. Just like in Cubism, the object ends up being transformed, rendered nearly unrecognizable to its original form by having been taken apart and conveyed based on its components, then re-constructed on more planes than the naked eye can fully behold. The same is true of my next example…
5) Does This Photoshop Make Me Look Fat?: We are no longer satisfied with truthful representations of human bodies. In fact, we might not even really believe the truth any more if it were given to us. We have been carried away- in the beginning unaware, later blissfully aware- by the movement to re-architect human anatomy through Photoshop. I admit I have visited blogs and websites that show the blunders of graphic artists and I often STILL can’t see that anything is wrong with the images. It is that nefarious. We are more content to see human bodies through the lens of Photoshop than through reality.

6) Branded Space: this is an old feature, the fact that we see in everything a chance to advertise or place products, but one recent example was so blatant I can’t fail to mention it here. It was very recently announced that in his next movie, James Bond will be sipping not a martini, but aHeineken. That’s right, 007’s drink of choice has received the ouster in favor of product placement. Needless to say, the reaction has not been, er, positive. But it is yet another example of the New Aesthetic- not only do we see even everyday objects and products through new physical lenses, we continue to see them through figurative lenses that are colored according to which advertiser has the most money to spend that day. So the object is not permitted to exist alone for us any more. Its meaning is always stamped across its face.

In fact, Maybe the weirdest aspect of this movement is how eminently consumable it is. It’s practically Warhol-esque in its commercial viability. A perfect example being how Facebook just gobbled up Instagram, the popular hipster-making photog app for $1B. But there are thousands more examples on the official New Aesthetic Tumblr. Let the New Aesthetic binge begin.
One last expression for you: Analog Recidivism: Actually, I’m just hoping this will somehow emerge as a reaction to the New Aesthetic. I think one of the next evolutions of the movement will be to feature in art, culture, social customs, etc. what we just don’t see any more as a result of our attachment to viewing the world through the lens of our gadgets and technology. Instead of showing us how our views have changed and been modified, somehow we will be shown what we just didn’t see as a result of staring at a phone, a computer, a tablet, etc. The little things we no longer notice or take note of will be featured as once again novel by virtue of the fact that we, physically, are no longer trained to see or look for them. Did I just blow your mind?
To read more on the New Aesthetic:
http://booktwo.org/notebook/sxaesthetic/
http://www.riglondon.com/blog/2011/05/06/the–new–aesthetic/
http://new–aesthetic.tumblr.com/
http://www.wired.com/beyond_the_beyond/2012/04/an–essay–on–the–new–aesthetic/



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}